Minesweepers CS 175: Project in AI (in Minecraft)
Video
Project Summary
It’s a minesweeper solver! It can solve any board, with any size, and exactly compute every cell’s chance of being a mine. It achieves this through advanced combinatorial and probability analysis with artificial intelligence. The project will use random search as the baseline algorithm, naive search as the intermediate algorithm and Q-Learning as the advancing algorithm.
What is Minesweeper?
Just in case you don’t know how the game works: Minesweeper is a single-player puzzle game avaliable on several avaliable operating systems and GUIs. At the start of the game, the player receives a rectangular grid of covered cells. Each turn, player may probe or uncover a cell revealing either a mine or an integer. This integer indicates the number of mines adjacent to the particular cell. As such, the number ranges from 0 to 8, since it’s impossible for a cell to have more than eight neighbors. The game ends when player probes a cell containing a mine (lose), or uncovered every cell that does not contain a mine (win).
Game Setup:
| Board With Cover | Board Without Cover |
|---|---|
 |
 |
The color of block indicates how many mines are nearby.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
Approaches
 Random Search
Random Search
You might realize that this is basically the most stupid way to find solution to the game.
Data for random search approach is generated in the following manner. Each tile in the game board is a Tile class. All the tiles are stored in a 2-dimensional list, and their locations, in terms of row and column, are represetned by list index.
Random search will keep generating two random integer as the location of next tile to be uncovered until the tile is guaranteed to be inside the board and staying covered.
#Alogrithm 1 sweep_random
while not game over do:
while True:
randomly select a tile
if the tile is covered and the cell is inside the board:
sweep the tile
return the tile's location
end if
end while
Naive Search
Data for Naive search approach is generated in the following manner. Each tile can be represented as a feature with an integer determined by the tile state in current board. If the tile is uncovered, the corresponding feature is represented by the number of mines to which the square is adjacent. The integer value is stored in tile class as COUNTER attribute. If the tile is uncovered, COUNTER attribute will be set to 0 by default since it does not provide any information. And the tile class also stores whether the tile is visible to the player with an visible value.

At each state the game, the naive search stores all tiles that are not visible, but are adjacent to visible tiles in perimeter. Moves are chosen randomly from tiles within the perimeter with some fixed probability, and otherwise just use random search. This method models normal game play where most moves are selected from the perimeter of the current board. However, our algorithms do not flag tiles indicating a mine is present like in real life; they only predict whether a tile is suitable to be a next move. The general greedy algorithm for naive_search is presented below:
while not game over do:
for all the tiles in the current board:
if the tile is invisible and the tile is adjacent to visible tiles:
add the tile to primeter
get surronding tiles of the current tile
calculate probability of the current tile being a mine
end if
choose a tile with minimum probability of being a mine.
sweep the tile
end while
Q-Learning
One approach is to model Minesweeper game as an Markov Decision Process and use a modified version of Q-Learning to discover the best moves for each given board state. After learning the Q values, the algorithm would then use rewards obtained to play the game.

This is a standard Q-Learning algorithm form. This function allows the algorithm to learn not just about the direct reward of a particular action, but also a particular action is more likely to lead to reward in a long-term. However, while common chess games are more concerned with endgame result, minesweeper is more interested in intermediate reward: whether the tile contains a mine. Therefore, to better approximate this reward, we remove dicount factor and estimate of optimal future value:
By giving reward for choosing a mine tile to be a negative number (for example, -1), and that of choosig a non-mine tile to be a positive numebr(1), we are able to find the tile which is least likely to be a mine with the highest Q value.
while not game over do:
s = current state of the board
sweep at random location
if tile is mine:
r = -1
else:
r = 1
end if
Q(s,a) = (1-alpha)*Q(s,a) + alpha(r)
end while
Evaluation
Three approaches are tested on two boards with different size and mine density.
Win Rate
We use win rate as the most important metric to understand how our approaches perform in playing Minesweeper:
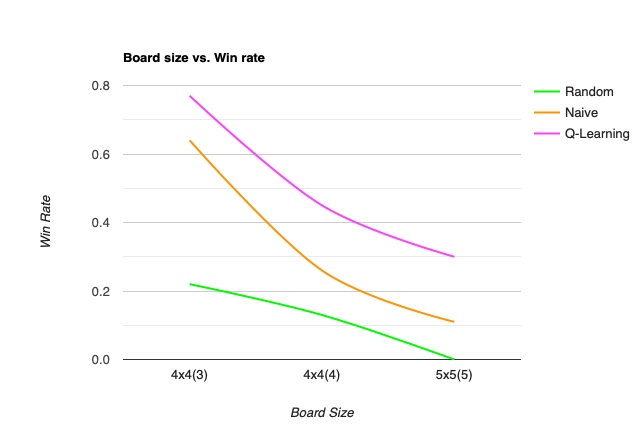
In the 4x4 board with 3 mines, all approaches except random choose exhibit moderate success; the Q-Learning approaches with almost 80% accuracy. However, the performance of three approaches drops after the board size increases. This is reasonable since, when playing Minesweeper, the game will automatically flip any adjcent non-mine tiles. Larger game board also means more chances to make decision. For method like random choose, it is almost impossible for it to consecutively choose correct tiles. As shown above, for a board larger than 5x5, it becomes harder for all approches to have satisfied probability of correct guess.
Number of Mines
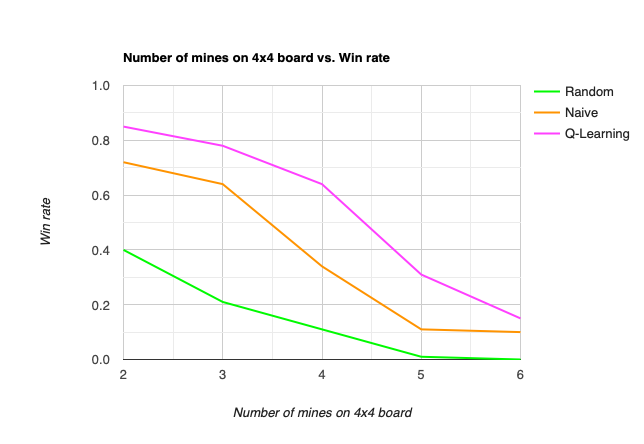
The result shows that the win rate drops quickly with increasing mine density: a game with higher mine density is simply harder to win because a board with more mines has far more layouts. Consider a board with size and p mines in total, where
. On this board, the total number of distinct configurations equals to
. A greater number of possible board configurations means a more chanllenging game because it creates a huge state space that makes every move less certain.
Number of Training
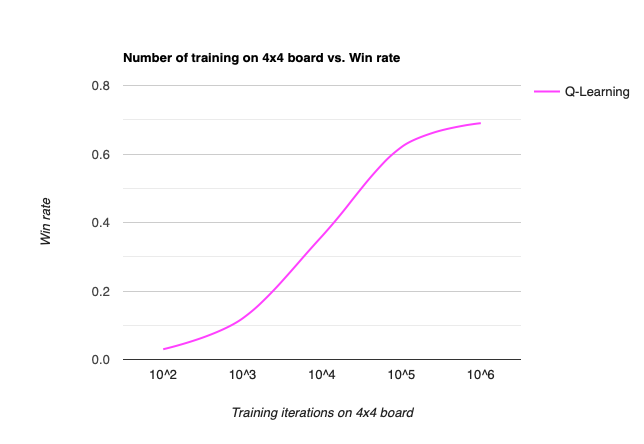
While Q-learning shows the best result, it also suffers from its large state space. On a Minesweeper game board, each tile can hold 9 possible values (0-8 for counter, 9 for invisible). Thus the upper bond for total game board configurations is . While in reality the true number of possible game configurations is smaller (due to of large number of inconsistent boards), the number still proves that the state space of Q-learning explodes when the board size increases. Also, for the same state visited before, it is possible that mines hide under different tiles, so we must visit a state many times in order to accurately approximate the probability of whether each tile is not a mine.
References
see /docs/references
Charts are made in (https://www.rapidtables.com)
Block images are provided by (https://www.minecraftinfo.com)
Video is made by iMovie and QuickTimePlayer